In an era driven by data, automation, and large-scale digital publishing, efficiency is the ultimate competitive advantage. Whether you are managing complex database architectures, developing enterprise software, or executing a large-scale programmatic SEO (pSEO) campaign, handling repetitive data manually is a recipe for stagnation.
Enter the Master Information Block (MIB).
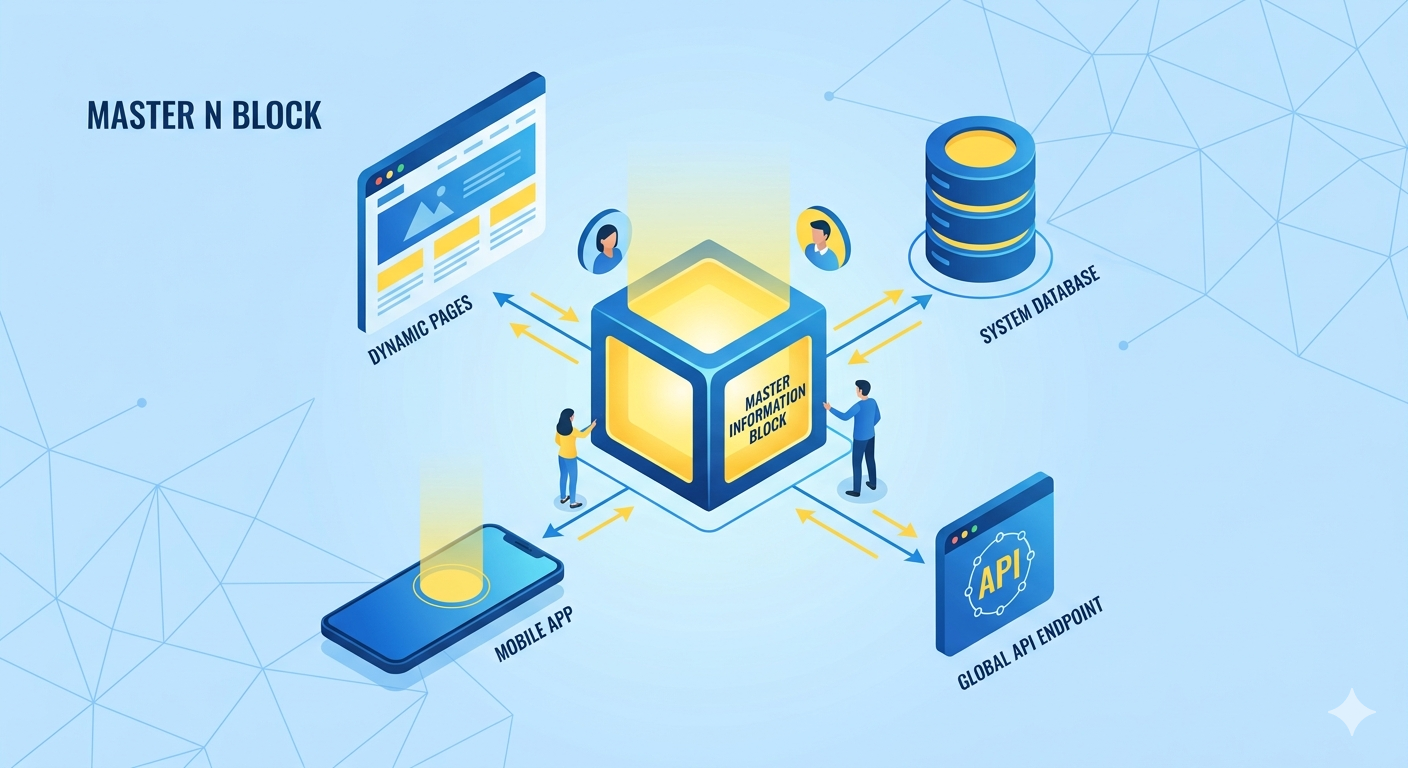
A Master Information Block is a foundational data-management design pattern. It serves as a centralized, standardized, and reusable repository of core information that can be dynamically injected across multiple platforms, pages, or systems. By establishing a single source of truth, an MIB eliminates data redundancy, minimizes human error, and radically accelerates content and development workflows.
This ultimate guide breaks down everything you need to know about Master Information Blocks, how they work, and how to implement them to scale your digital infrastructure.
Understanding the Core Concept: What is an MIB?
At its core, a Master Information Block functions similarly to a “global variable” in programming or a “master component” in UI/UX design. Instead of rewriting or re-entering core data sets across hundreds of different locations, you define the data once within the MIB.
[ Master Information Block ]
│
├─► Dynamic Page A (Auto-populates)
├─► Database Table B (Syncs instantly)
└─► API Endpoint C (Distributes globally)
When any variable inside the Master Information Block is updated, that change automatically propagates across every single connected entity in real-time.
The Core Components of an MIB
A robust Master Information Block typically consists of three layers:
- The Schema / Schema Attributes: The structured data fields (e.g., strings, integers, booleans) that define what information the block holds.
- The Data Core: The actual authoritative values stored within those fields.
- The Distribution Mechanism: The APIs, tokens, shortcodes, or database queries that fetch and display the data where needed.
Why Master Information Blocks Matter for Scalability
Operating without a centralized information block creates massive operational friction. If your organization changes a core metric, a primary address, a product specification, or a foundational boilerplate text, manual updates require hours—or days—of tedious auditing.
1. Eliminating Redundancy (DRY Principle)
In software development and data architecture, the DRY (Don’t Repeat Yourself) principle is sacred. MIBs enforce this strictly. By keeping data in one block, you avoid bloating databases with duplicated records.
2. Radical Time Efficiency
For digital publishers and pSEO specialists building thousands of localized landing pages or data-driven posts, hardcoding information is impossible. An MIB allows you to spin up massive content hubs where the layout remains consistent, but the core informational blocks adapt instantly based on user intent or database filtering.
3. Absolute Data Integrity
When data is modified in only one authoritative location, the risk of conflicting information across your web properties drops to zero. This builds immense trust with both users and search engine crawlers, who reward consistent, accurate data structures.
Step-by-Step: How to Design and Implement an MIB
Building an effective Master Information Block requires careful planning before execution. Follow this structured blueprint to deploy your first MIB.
Step 1: Data Identification and Scoping
Audit your system or content cluster to isolate data points that are used repeatedly. These could include corporate metadata, technical specifications, system configurations, or foundational definitions. If a piece of data appears in more than three places, it belongs in an MIB.
Step 2: Structure the Schema
Define the datatypes clearly. Ensure that your keys are highly descriptive and standardized. For instance, instead of using a vague key like info1, use explicit semantic naming conventions like company_global_revenue or product_baseline_dimensions.
Step 3: Choose Your Implementation Stack
Depending on your environment, the technical execution will vary:
- For Web Publishers / WordPress: Utilize advanced custom fields (ACF) combined with global options pages or custom shortcodes.
- For Software Developers: Implement centralized JSON/YAML configuration blocks or dedicated microservices that serve the MIB via REST or GraphQL APIs.
- For Database Administrators: Utilize master lookup tables with relational foreign keys ensuring strict cascading updates.
Step 4: Establish the Validation and Security Layer
Because an MIB alters data globally, a single typo can corrupt thousands of front-end outputs. Implement strict validation rules (e.g., JSON Schema validation) and restrict write-access to authorized administrators or automated system webhooks.
Best Practices for Managing Your Information Blocks
To ensure your Master Information Blocks remain clean, performant, and easy to maintain over time, adhere to these professional standards:
- Keep Blocks Modular: Do not create a single, massive MIB that holds thousands of unrelated data points. Instead, create specialized, smaller blocks (e.g., a Legal Disclaimer Block, a Technical Spec Block, or a Pricing Matrix Block).
- Document Your Keys: Maintain a clear, accessible data dictionary explaining exactly what each variable inside the block represents.
- Implement Version Control: Track changes to your master blocks using Git or automated database logging so you can instantly roll back updates if a global modification breaks front-end elements.
- Optimize for Performance: Cache the output of your MIBs. Since this data is read frequently but modified rarely, heavy caching prevents unnecessary database strain or API latency.
Comprehensive FAQ Section (Deep-Dive Inquiries)
This detailed FAQ section addresses advanced architectural queries, technical edge cases, and optimization strategies regarding Master Information Blocks.
General & Conceptual Fundamentals
What exactly is the difference between a Master Information Block and a standard database row?
A standard database row represents a single entity within a specific table (e.g., user ID 402 or product ID 99). A Master Information Block, however, is a structural design pattern meant for global distribution and architectural reuse. While an MIB can technically be stored within a database row, its purpose is to act as an authoritative configuration or content layer that maps horizontally across multiple distinct tables, systems, or webpage templates.
Can a Master Information Block contain dynamic logic, or must it remain strictly static?
An MIB can absolutely contain conditional logic, loops, or tokens. While the source data inside the block is typically static and structured, the distribution engine processing it can evaluate context before rendering. For example, an MIB handling pricing data can include dynamic logic to automatically convert currencies or calculate localized tax rates on the fly based on the user’s IP address.
Is the term “Master Information Block” exclusive to web development?
No. The concept originates from broad information systems architecture and systems engineering. It is used extensively in industrial automation (Programmable Logic Controllers or PLCs), telecommunication protocols (where Master Information Blocks contain essential cell configuration data), database design, and large-scale digital publishing architectures like programmatic SEO.
Technical Architecture & Implementation
How do you handle API latency when fetching a Master Information Block across a distributed network?
When an MIB is requested by multiple decoupled microservices or front-end applications, API latency can degrade user experience. The best way to mitigate this is by implementing a multi-tier caching strategy:
- Edge Caching (CDN): Store the rendered JSON/XML output of the MIB at the CDN level (e.g., Cloudflare Workers or Fastly).
- In-Memory Key-Value Stores: Use Redis or Memcached within your application stack to serve the block instantly without running heavy database queries.
- Stale-While-Revalidate (SWR): Configure your system to serve the cached MIB immediately while asynchronously fetching updates in the background.
What are the risks of nesting one Master Information Block inside another?
Nesting blocks (creating dependencies where MIB-A calls a variable from MIB-B) can be powerful but dangerous. The primary risks include:
- Circular Dependencies: If MIB-A references MIB-B, and MIB-B inadvertently references MIB-A, the parser will enter an infinite loop, causing server crashes or stack overflows.
- Debugging Friction: Tracing data errors becomes exponentially harder as the nesting depth increases.
- Performance Degradation: Deeply nested structures require recursive parsing, which consumes significantly more CPU cycles and database join operations. Limit nesting to a maximum of two layers.
How should schema evolution be managed when an existing MIB needs new fields?
As business requirements change, your MIB schema will inevitably evolve. To prevent breaking downstream applications:
- Always Add, Never Delete: Treat the MIB schema as an immutable contract. Append new data fields as optional keys rather than deleting or renaming older, legacy keys.
- Implement SemVer (Semantic Versioning): If structural breaking changes are mandatory, version your MIB (e.g.,
/v1/master-blockand/v2/master-block). This allows older systems to migrate gradually without immediate downtime.
SEO, Content Strategy & Optimization
How do search engines like Google view the use of Master Information Blocks across thousands of pages?
Search engines favor accuracy, structured data, and fast load times—all of which are optimized by using MIBs. When you use an MIB to inject precise data clusters (like technical specifications or accurate tabular data) consistently across your site, it helps Google’s crawlers build a clear semantic understanding of your content entities.
Does using an identical informational block across multiple pages cause duplicate content penalties?
No. Google does not penalize sites for having recurring boilerplate sections, helpful data blocks, or sitewide disclaimers, provided the overall page offers unique, contextual value. In fact, using an MIB ensures that crucial information remains perfectly consistent across your domain, which is a positive indicator for Google’s E-E-AT (Experience, Expertise, Authoritativeness, Trustworthiness) evaluation.
Can I inject schema markup directly through a Master Information Block?
Yes, and this is highly recommended. You can structure your MIB to output both the visible front-end content and the matching JSON-LD schema markup (such as Product, Organization, or FAQ schemas) simultaneously. This ensures your metadata perfectly matches your visible on-page content, reducing the chance of search console schema errors.
Security, Governance & Troubleshooting
Who should have editing access to the Master Information Block in an enterprise setting?
Because modifying a Master Information Block alters data across your entire digital footprint, access control must be strictly managed. Use Role-Based Access Control (RBAC):
- Read Access: Granted globally to all connected software, APIs, and content creators.
- Write/Edit Access: Restricted strictly to senior data architects, product owners, or lead developers.
- Approval Workflows: Implement a staging or pull-request system where changes to the MIB must be peer-reviewed and tested before deploying to production environments.
What is the most effective fallback strategy if an MIB fails to load or corrupts?
If a network partition or database error prevents the MIB from loading, your front-end should never display blank spaces or raw code tokens like {{master_error}}. Implement a robust fallback array:
- Hardcoded Defaults: Set your application to catch loading errors and replace missing variables with safe, generalized default strings.
- Static Build Fallbacks: For Jamstack or statically generated sites, ensure the last successful build remains live until the MIB data stream recovers completely.
How do you audit historical changes made to a specific data value inside an MIB?
To maintain data transparency and regulatory compliance, pass all MIB edits through an audit logging middleware. Every time a value is changed, the system should log the Timestamp, the User/API key responsible, the Old Value, and the New Value. Storing these logs in an append-only ledger or a dedicated database table ensures you can quickly pinpoint when and why an incorrect entry was introduced.